近日,在国际顶级图学习标准OGB(Open Graph Benchmark)挑战赛中,第四范式凭借AutoML(自动机器学习)技术,在与斯坦福大学、康奈尔大学、Facebook、阿里巴巴等国际顶尖高校与科技巨头同场竞技中脱颖而出,以较大优势斩获ogbl-biokg、ogbl-wikikg2两项任务榜单第一。
近年来,知识图谱因可挖掘实体之间的潜在关系、提供更高效的搜索结果,被广泛应用在智能搜索、智能问答、社交网络、金融风控等诸多行业应用中。作为知识图谱领域重要的技术手段,图学习已成为机器学习最重要的研究领域之一,受到了学术界和工业界的广泛关注。
OGB是目前公认的图学习基准数据集代表,由斯坦福大学Jure Leskovec教授团队建立,于2019年国际顶级学术会议NeurIPS上正式开源。其囊括了节点性质预测、边性质链接预测、图性质预测等知识图谱领域众多权威赛题,以质量高、规模大、场景复杂、难度高著称,素有知识图谱领域“ImageNet”之称,成为众多科技巨头、科研院所和高校团队试验技术成色的试金石。
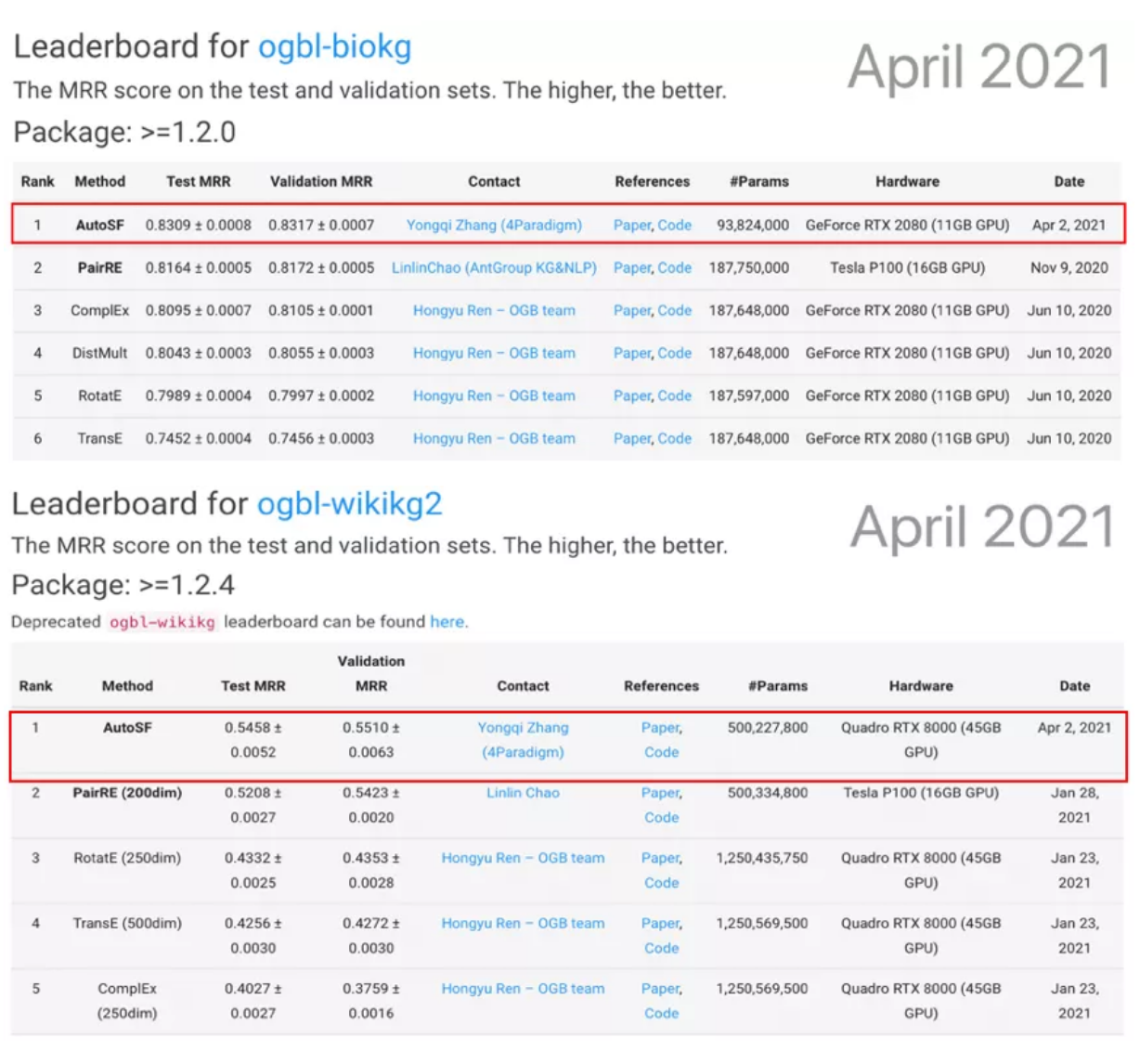
此次,第四范式参与了ogbl-biokg、ogbl-wikikg2两项数据量庞大且极具业务价值的知识图谱链接预测任务,均在处理嘈杂、不完整知识图谱等方面挑战巨大。其中,ogbl-biokg包含多个海量生物医学知识库,构成了500多万个三元组(实体-关系-实体、实体-属性-属性值),在药物属性预测及生物医学研究方面具有重要意义。ogbl-wikikg2来源于Wikidata知识库,需要在1700多万个事实三元组中精准预测实体间的潜在关系,可有效提升推荐系统、智能问答等场景应用效果。
为了精准理解数据集中复杂语义信息、挖掘潜在关系,业界通常以评分函数(SF)作为衡量知识图谱中三元组可编程性的重要指标,但现有评分函数设计仅专注于某一类语义模型,无法应对实际应用中千变万化的知识图谱任务场景。
受AutoML启发,第四范式本次采用AutoSF(自动评分函数)参赛,通过理解生物医学、维基百科等复杂知识图谱中的不同语义信息,设计出更符合场景认知特性的评分函数,实现在对应任务上的性能突破。同时,AutoSF设计的评分函数可高效利用模型参数,在具有更小模型复杂度的基础上,预测性能位居第一,以较大优势超过PairRE、TransE、ComplEx、RotatE等其他知名评分函数。

